Hypothetical Decentralised Social Media Protocol Stack
if we were to dream up the Next Social Media from first principles we face three problems. one is scaling hosting, the second is discovery/aggregation, the third is moderation.
hosting
hosting for millions of users is very very expensive. you have to have a network of datacentres around the world and mechanisms to sync the data between them. you probably use something like AWS, and they will charge you an eye-watering amount of money for it. since it’s so expensive, there’s no way to break even except by either charging users to access your service (which people generally hate to do) or selling ads, the ability to intrude on their attention to the highest bidder (which people also hate, and go out of their way to filter out). unless you have a lot of money to burn, this is a major barrier.
the traditional internet hosts everything on different servers, and you use addresses that point you to that server. the problem with this is that it responds poorly to sudden spikes in attention. if you self-host your blog, you can get DDOSed entirely by accident.
scaling hosting could theoretically be solved by a model like torrents or IPFS, in which every user becomes a ‘server’ for all the posts they download, and you look up files using hashes of the content. if a post gets popular, it also gets better seeded! an issue with that design is archival: there is no guarantee that stuff will stay on the network, so if nobody is downloading a post, it is likely to get flushed out by newer stuff. it’s like link rot, but it happens automatically.
IPFS solves this by ‘pinning’: you order an IPFS node (e.g. your server) not to flush a certain file so it will always be available from at least one source. they’ve sadly mixed this up in cryptocurrency, with ‘pinning services’ which will take payment in crypto to pin your data. my distaste for a technology designed around red queen races aside, I don’t know how pinning costs compare to regular hosting costs.
theoretically you could build a social network on a backbone of content-based addressing. it would come with some drawbacks (posts would be immutable, unless you use some indirection to a traditional address-based hosting) but i think you could make it work (a mix of location-based addressing for low-bandwidth stuff like text, and content-based addressing for inline media). in fact, IPFS has the ability to mix in a bit of address-based lookup into its content-based approach, used for hosting blogs and the like.
as for videos – well, BitTorrent is great for distributing video files. though I don’t know how well that scales to something like Youtube. you’d need a lot of hard drive space to handle the amount of Youtube that people typically watch and continue seeding it.
aggregation/discovery
the next problem is aggregation/discovery. social media sites approach this problem in various ways. early social media sites like LiveJournal had a somewhat newsgroup-like approach, you’d join a ‘community’ and people would post stuff to that community. this got replaced by the subscription model of sites like Twitter and Tumblr, where every user is simultaneously an author and a curator, and you subscribe to someone to see what posts they want to share.
this in turn got replaced by neural network-driven algorithms which attempt to guess what you’ll want to see and show you stuff that’s popular with whatever it thinks your demographic is. that’s gotta go, or at least not be an intrinsic part of the social network anymore.
it would be easy enough to replicate the ‘subscribe to see someone’s recommended stuff’ model, you just need a protocol for pointing people at stuff. (getting analytics such as like/reblog counts would be more difficult!) it would probably look similar to RSS feeds: you upload a list of suitably formatted data, and programs which speak that protocol can download it.
the problem of discovery – ways to find strangers who are interested in the same stuff you are – is more tricky. if we’re trying to design this as a fully decentralised, censorship-resistant network, we face the spam problem. any means you use to broadcast ‘hi, i exist and i like to talk about this thing, come interact with me’ can be subverted by spammers. either you restrict yourself entirely to spreading across a network of curated recommendations, or you have to have moderation.
moderation
moderation is one of the hardest problems of social networks as they currently exist. it’s both a problem of spam (the posts that users want to see getting swamped by porn bots or whatever) and legality (they’re obliged to remove child porn, beheading videos and the like). the usual solution is a combination of AI shit – does the robot think this looks like a naked person – and outsourcing it to poorly paid workers in (typically) African countries, whose job is to look at reports of the most traumatic shit humans can come up with all day and confirm whether it’s bad or not.
for our purposes, the hypothetical decentralised network is a protocol to help computers find stuff, not a platform. we can’t control how people use it, and if we’re not hosting any of the bad shit, it’s not on us. but spam moderation is a problem any time that people can insert content you did not request into your feed.
possibly this is where you could have something like Mastodon instances, with their own moderation rules, but crucially, which don’t host the content they aggregate. so instead of having ‘an account on an instance’, you have a stable address on the network, and you submit it to various directories so people can find you. by keeping each one limited in scale, it makes moderation more feasible. this is basically Reddit’s model: you have topic-based hubs which people can subscribe to, and submit stuff to.
the other moderation issue is that there is no mechanism in this design to protect from mass harassment. if someone put you on the K*w*f*rms List of Degenerate Trannies To Suicidebait, there’d be fuck all you can do except refuse to receive contact from strangers. though… that’s kind of already true of the internet as it stands. nobody has solved this problem.
to sum up
primarily static sites ‘hosted’ partly or fully on IPFS and BitTorrent
a protocol for sharing content you want to promote, similar to RSS, that you can aggregate into a ‘feed’
directories you can submit posts to which handle their own moderation
no ads, nobody makes money off this
honestly, the biggest problem with all this is mostly just… getting it going in the first place. because let’s be real, who but tech nerds is going to use a system that requires you to understand fuckin IPFS? until it’s already up and running, this idea’s got about as much hope as getting people to sign each others’ GPG keys. it would have to have the sharp edges sanded down, so it’s as easy to get on the Hypothetical Decentralised Social Network Protocol Stack as it is to register an account on tumblr.
but running over it like this… I don’t think it’s actually impossible in principle. a lot of the technical hurdles have already been solved. and that’s what I want the Next Place to look like.
This is something that I have been daydreaming about for a long time also. I agree by far the biggest problem would be to actually get people to use it, but still it’s interesting to think about the technical issues…
I think aiming specifically to “recreate tumblr” actually helps with some of the questions. If people routinely reblog posts, then it would be natural for them to also “seed” those posts, giving some redundancy. The client could store posts that you have viewed locally, so that they don’t go away too easily and you can reblog them later if the links rotted.
Also, the way to discover content/users on tumblr is that you see it reblogged by someone you follow, so there is no recommendation algorithm that can be manipulated. There is a trade-off between privacy and discoverability: if (like Twitter) likes and follows are public, then anyone can make “client-side” recommendations based on “liked by somebody who is followed by many users that you follow”, etc.
Making follower/following-lists are public would also have a nice bonus effect on direct messaging. You can always sign and publish the public keys of anyone you interact with, to construct a PGP-style web-of-trust. This system would be really resistant to eavesdropping. As soon as you knew even a single correct identity (e.g. because someone emailed it or published it on their web page or gave you a physical business card), then any attempt to man-in-the-middle you would instantly unravel. We could have secure communications without needing a centralized certificate authority.
Apart from data availability, I think some other problems are:
Naming. One problem with P2P systems is that it’s hard to create globally unique nicknames. I want to be “youzicha”, but without a central party, how can you enforce that nobody else uses the same nickname? Actually, nowadays you can use a blockchain to do it, but this is pretty heavy-handed, you would need to include some kind of rationing or payments or proof-of-work to prevent people from immediately nickname-squatting every short name. I think it’s better give up on unique names altogether, so that people’s unique identifier is just their public key, and then they can publish whatever metadata they like to make themselves easier to find. ICQ used to work this way, with users being identified by just a number but no human-readable nickname.
Anonymization. We don’t think about it so often, but one service that centralized companies provide to us is to act as anonymizing proxies. It works both ways: I can publish this tumblr pseudonymously as “youzicha” without disclosing my real-world identity, and also I can look at peoples post on Twitter and Tumblr without them being aware of it. If everything was purely P2P, you would see each page view (and the IP-address of the person who made it) in real-time, which seems like a nerve-wracking experience.
I think this is a genuine advance: back in the old Usenet days people generally posted under their full government names, which maybe worked well because Usenet as a whole was a kind of subculture, but now people constantly doxx each other and having the wrong political opinions can damage your career. (C.f. the debate surrounding Facebook, Google+ and their “real names” policy.) If the system doesn’t provide anonymity it seems important to at least make this fact very clear in the user interface, users could get burnt. Maybe automatically do some IP geo-lookups to illustrate the kind of information it leaks.
Blocklists, spam, harassment. As you noted above this seems like a big problem.
But if implemented well it could be a selling point, because the current solutions are so disliked. On the being-censored side, sites like Hacker News and Twitter play weird mind games to secretly shadow-ban you, which feels disrespectful. On the censoring sites, people who deal with a lot of incoming messages find the current blocking solutions too blunt. If you provided an elaborate (Turing complete?) policy language, a thousand flowers could bloom: shared blocklists, “topics” like USENET newsgroups which anyone can post to, and then “overlay” newsgroups which are moderated, etc. Popular bloggers could do the Luna thing where you have pay them (using some cryptocurrency) to see your message.
Peoples could publish their rules for receiving messages, which would serve several purposes. First, clients can avoid routing messages which would be discarded anyway (a kind of distributed DoS-protection, as a replacement for Cloudflare). Second, your client software can usefully advice you (“sorry, because of spam rules this message cannot be sent to PopularBlogger. In order to unblock it, do one of (1) build up a posting history of n messages on X Forum, (2) have your message approved by a moderator in group Z, (3) get a friend-of-a-friend introduction from one of the following people, …”). And most importantly, you can performatively block Nazis and post really elaborate DNI lists.
Beheading and child abuse videos. I think this is a bigger problem than “if we’re not hosting any of the bad shit it’s not on us”, because if a social media system is truly censorship-resistant the government will not allow it to exist for long. Interestingly, this is goes against some of the other desiderata: you’d want it to not be anonymous, to make it easy for the police and/or online vigilantes to chase down criminals. And you might want content to not be discoverable. (E.g. if you use BitTorrent Mainline DHT you maybe interact with people who search for bad things, but since they only provide a SHA-1 hash you never know.)
so when i say ‘no deletes’ it’s a little complicated. since this post is getting a little traction, let me explain some of the technical stuff in more detail.
the way content-based-addressing works is, instead of linking to a place on the internet (a specific server), you use something called a hash that’s computed from the file itself.
for example, let’s say you have a picture you want to share over IPFS. this picture, say.
If I have a copy of this picture, I can compute something called a hash function. The hash function is essentially a pseudo-random scrambling of the data, which is usually much smaller than the actual data. For example, the SHA-256 hash of luciano.webp here is, in hexadecimal,
This is only 256 bits, much smaller than the actual 106KB file.
The way hash functions work, it’s very very very unlikely for two files to have the exact same hash. You can’t ‘work backwards’ from the hash to the original picture, there’s not enough data in the hash, but if you know what the hash is, and someone sends you something they claim is luciano.webp, you can very easily verify that it’s (almost certainly) the picture you’re looking for.
So the idea of all this is that you start with the hash and track down someone who has the original file and get it from them.
The way BitTorrent originally worked is that there’s a computer called a ‘tracker’, which keeps track of everyone who has a copy of luciano.webp. You can say to the tracker ‘hey I’m looking for luciano.webp, who has it?’ and the tracker will send you a list, and then you can ask each of them for a copy. A torrent file is nothing more than a list of hashes and a list of trackers.
However, sometimes the tracker will go down. It’s a single point of failure. But there’s a way around this problem…
There’s a very clever bit of tech invented for BitTorrent called a Distributed Hash Table (DHT). This makes it so that every computer on the network can be a tracker. The hash itself is used as an address to look up the computers keeping track of who has luciano.webp.
So when you join the network, you will also become a tracker for certain files. You don’t know what those files are, since it’s all based on hashes. What’s great about this is that if a tracker goes down, another computer can sub in. The DHT gives a mechanism to determine who should be the trackers for each file.
IPFS, Interplanetary File System, is an attempt to use the same tech for websites. Basically, every time you download a file across IPFS, you hold onto a copy and let the trackers know that you have it, using the hash. If someone else comes looking for that file, you can serve it to them. When you download a file, you’ll find the nearest computer that has a copy and get it from them.
One nice thing about this is that if someone else posts luciano.webp on their blog, it’s already spread across the network, and so they can just download it from the nearest person.
Of course, you don’t have unlimited storage space, so sooner or later you run out. At this point, you “flush” the oldest files that nobody has asked for recently – delete them from your computer, and tell the trackers you don’t have them anymore.
So if it’s not being downloaded, data gradually gets deleted from the computers on the IPFS. If you want data to stick around, you have to keep a computer running with instructions to never delete that file (this is called “pinning”), or pay someone else to do the same.
So when we say ‘things can’t be edited or deleted’, it’s complicated. Once you publish a file onto IPFS, it’s hard to purge it from the network quickly. If you wanted to put up version 2 of a post, people can still look up version 1 using the hash of version 1. You can delete version 1 from your computer, and tell everyone the hash of version 2, but the version 1 will stick around. (There are ways around this in IPFS – see here, here – which let you direct people to the most up to date versions of a site/file.)
So to get rid of something after you’ve released it to IPFS, you have to have everyone get rid of it. But wait around long enough, and if nobody is pinning it, and nobody is still downloading it… that file will get deleted sooner or later.
Despite the very different underlying tech, functionally this is actually pretty similar to how Tumblr already works. Once something gets reblogged, it’s out of your hands, you can’t edit or delete the copy they have on their blog. (This is in contrast to a service like Twitter, where if you delete a Tweet, it also deletes the retweets. In programming jargon, Tumblr reblogs copy by value, while Twitter retweets copy by reference.)
On Tumblr, old posts tend to be very hard to find – people delete their blogs, or change URLs, and the search sucks. On IPFS on the other hand, old posts might be flushed off the network.
So it wouldn’t be much different in practice.
Tags:
#man‚ I am so disappointed by the shining potential of IPFS getting eaten by Generic Crypto Shit #I used to run a node #(but network effects meant that I never encountered a webpage that I both wanted to pin and could meaningfully pin) #(so few of them being IPFS-based) #I used to read their newsletter #(but I noticed one day that it had been so long since #the newsletter had mentioned progress or even *hopes* towards the beautiful‚ resilient meshnet whose seed I saw in them) #I don’t know‚ have they ever recovered their course? #…I also kind of want to check in on Scuttlebutt now and see how they’re doing #The Great Tumblr Apocalypse #IPFS #disappointed permanent resident of The Future #101 Uses for Infrastructureless Computers #this probably deserves some warning tag but I am not sure what #this post was queued because my to-reblog list is too long and I didn’t want to dump it on you all at once
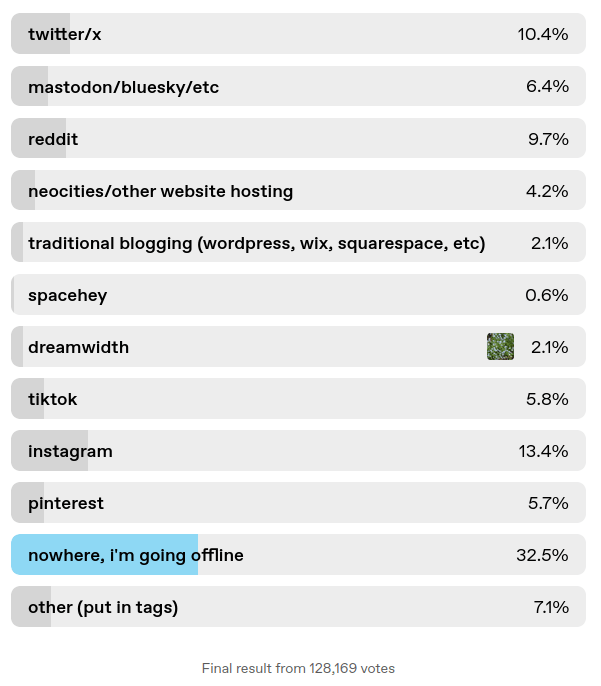
sometimes you hear people muse, “why did we ever start putting all our online content in these untrustworthy centralized walled gardens?” anyhow this is why
Man yeah when’s the last time you heard of someone getting Slashdotted?
Before this, I mean.
Tags:
#disappointed permanent resident of The Future #this post was queued because my to-reblog list is too long and I didn’t want to dump it on you all at once
smartphone storage plateauing in favor of just storing everything in the cloud is such dogshit. i should be able to have like a fucking terabyte of data on my phone at this point. i hate the fucking cloud
this is gonna make me sound very Old Man Yells At Cloud but i just hate how many things in my life assume i will always have access to a quick, reliable internet connection and almost cease to function without it. Obviously certain things Have To Have An Internet Connection, but i want to be able to listen to music if my service is bad. i want to still watch movies if Netflix is down. i want to have a working map when i can’t get a cell signal. nearly every tech product these days bears the fingerprint of the extremely internet-rich places they are developed, high rent offices in Seattle, San Francisco, etc.. I think often the idea of the internet not being available is so remote to them it doesn’t even factor in to development. i remember when the Xbox One was debuted and Microsoft was almost mockingly like “if you don’t have reliable fast internet, then don’t bother buying this”, and there was such backlash they completely went back on so much of that. But now that attitude is just the tech norm.
I don’t trust the cloud.
This makes me happy I don’t use my phone for going online
i mean you can get a terabyte phone but it costs like $1600 USD (give or take a couple hundred, idk, i’m not looking it up)
what really pisses me off is that the samsung flagship phones have completely phased out their sd card slots. you can’t get a cell phone with expandable storage anymore
Yeah, it’s such bullshit that it’s a whole ordeal to dig up a model with a microSD slot now.
I *do* have a 2020-model phone (a slightly different model of which is still in production) with a half-terabyte microSD† in it. (For CAD$155 instead of CAD$70 I could have gotten a full terabyte of microSD, but I didn’t have the budget. Mind you, I *could* upgrade later, without having to replace the whole phone…) But that’s because a microSD slot was my single highest priority when deciding what model to buy, absolutely non-negotiable: if I’d cared any less, I’d probably have ended up with a Pixel or a OnePlus.
—
Hmm, I wrote an extremely outdated guide to orienting your phone setup around not having reliable Internet access in 2015, and a substantially outdated guide in 2018, so it sounds like I’m due for another one. Be right back.
†Some of the specs for that phone model you’ll see around will say it takes “up to 128 GB”, but don’t be fooled: 64 GB – 2 TB microSDs are the same backwards-compatibility tier. If a phone can take 32 GB, it might not be able to take 64, but if it can take 64 it can take 2048.
Tags:
#bringing this back since I’ve seen some of the more despairing versions of this thread being passed around again recently #and yes‚ I do have a copy of my Tumblr on my phone #multiple copies‚ in fact: [a tumblr-utils output] and [a scrape of my WordPress mirror converted to Kiwix format] #(and technically also the text-only export from WordPress but I *really* don’t want to have to bootstrap from that one) #(that one is very last-resort) #(cheap‚ though: 6.8 MB) #101 Uses for Infrastructureless Computers #disappointed permanent resident of The Future #proud citizen of The Future #Brin owns *two* 2010’s computers now #fun with loopholes #this post was queued because my to-reblog list is too long and I didn’t want to dump it on you all at once
You’ll be able to make a custom feed to follow blogs, webcomics, social media feeds, podcasts, news, and other stuff on the web all in one place. To follow something, find its “feed URL”– often marked by an icon that looks like this ↓– and paste it into your reader of choice as a new feed.
Some feed URLs for social media:
Twitter: Feedbro can use Twitter profile URLs as feed URLs. Otherwise, use nitter.net/username/rss (or other Nitter instance) (You can get a CSV file of all the accounts you follow using “Download a user’s friends list” on Tweetbeaver)
Tumblr: Use username.tumblr.com/rss or username.tumblr.com/tagged/my%20art/rss to follow a blog’s “my art” tag (as an example)
Cohost: Use username.cohost.org/rss/public (WIP feature)
Instagram: Feedbro can use Instagram profile and hashtag URLs as feed URLs. Otherwise, Instagram doesn’t have RSS feeds, and due to aggressive rate limiting on their part, it’s not so simple to generate a feed URL.
Facebook: Feedbro can use public Facebook group/page URLs as feed URLs.
(If you know an artist who exclusively posts to Instagram, you may want to gently suggest that they crosspost elsewhere…)
*You can set up your subscriptions in one reader and import them into another by exporting an OPML file.
This!
RSS feeds were a great way to keep track of things before the rise of the platforms, and (if we’re smart) they’ll be great again.
Did you know? Many webcomics can be tossed into RSS feeds, depending on how the website is built, so you’ll get notifications every time they update! This includes:
Tumblr webcomics (using that tag thing listed above)
Self-hosted things that use any kind of WordPress installation
(Tapas and Webtoon are in the same boat as Instagram, where the developers have limited their RSS capabilities intentionally.)
RSS is a great solution for comics that update sporadically, too!
Tags:
#ooh‚ I’ll have to try out those Nitter and RSS-Bridge tricks #101 Uses for Infrastructureless Computers #PSA #this post was queued because my to-reblog list is too long and I didn’t want to dump it on you all at once
Python 3 script for backing up your Tumblor blog; I can confirm it works perfectly once you add your API key using the README instructions. I did have to pass –no-ssl-verify on the command line, because without that it spat out of a bunch of SSL failures, but other than that it worked (and very quickly too, my ~5000 posts took less than a minute)
WordPress itself also has an import tool that can bring Tumblr over to any WordPress blog- mine is up at https://thestonesgowalking.wordpress.com/ Just look for the ‘import’ tab under ‘tools’ in your dashboard there. WordPress has been showing an interest in the fediverse, so I’m hoping that at some point in the future I can double-import from Tumblr->Wordpress->Hypothetical Fediverse Thing, basically to keep blogging with as much continuity as possible and maintain a (theoretically) searchable history across platforms.
As always, multiple backups are better than one, so I’ll be using this python script as well. Tumblr isn’t being formally shuttered yet, but with @staff down to a skeleton crew, they won’t have as many resources to throw at hardware failures, technical snafus, and other such problems. You should take final responsibility for your own data at this point; don’t assume that you’ll get much warning if the worst does happen.
And of course, pour one out for the folks that put so much work in to the site. There was a phenomenal amount of human energy that went in to keeping our collective garbage fire burning, and I am, truly, so very grateful to them for that.
Tags:
#I can’t reblog The Post because jv turned off reblogs in an attempt to stem the overwhelming flood of Discourse #(Discourse with‚ disappointingly but unsurprisingly‚ quite a lot of bad reading comprehension) #((meanwhile the CEO‚ Tumblr user photomatt‚ is desperately doing damage control)) #((”there are amazing examples like OpenAI and Telegram running circles around much bigger players with small teams. #That’s what we hope to replicate.”)) #((”since people leaving Tumblr aren’t being laid off #they’re just switching to other teams within Automattic #if something doesn’t work or breaks we can always pull them back in to work on it.”)) #but really‚ when it comes down to it: #there isn’t much left for me to say that I have not already said #and very little left for me to feel that I have not already felt #y’all know where to find me #I keep a local copy of the list of Tumblrs I follow‚ and I’ll look y’all up elsewhere if need be #call this an evacuation drill #Tumblr’s final demise may or may not turn out to be causally downstream of this incident #but someday it *will* die #(…also‚ uh‚ contemplate LiveJournal’s current state for a few moments) #it’s just been declared Backup Awareness Week here on Tumblr‚ and I will be moving posts on digital preparedness to the front of the queue #as for this specific post: #I did not know there was a Python 3 version of tumblr-utils! #maybe I will be able to finally uninstall Python 2 now #I’ll have to test this out #Tumblr: a User’s Guide #recs #The Great Tumblr Apocalypse #101 Uses for Infrastructureless Computers #tag rambles
yudkowsky’s belligerence here is honestly adorable
What the fuck did you just fucking say about reality, you biased little bitch? I’ll have you know that reality graduated top of its class in the Level IV Multiverse, and has been involved in numerous quantum branches, and has over 10^80 confirmed particles. It is trained in the standard model and generates the top quark and all four fundamental forces. You are nothing to it but just another proper part. It will wipe you the fuck out with inevitability the likes of which has repeatedly been demonstrated on this Earth, mark my fucking words. You think you can get away with saying that shit to reality over the Internet? Think again, fucker. As we speak reality is contacting its pervasive configuration space across the observable universe and your light cone is being traced right now so you better prepare for the incredulity, maggot. The incredulity that wipes out the pathetic little thing you call your classical intuitions. You’re fucking quantum, kid. Reality is anywhere, anytime, and it can kill you in over seven hundred ways, and that’s just with vacuum collapse. Not only is reality extensively trained in modeling itself, but it has access to the entire arsenal of the Large Hadron Collider and it will use it to its full extent to wipe your miserable ass off the face of the wavefunction, you little shit. If only you could have known what unholy retribution your little “counter-intuitive” comment was about to bring down upon you, maybe you would have held your fucking tongue. But you couldn’t, you didn’t, and now you’re paying the price, you goddamn idiot. It will shit paradoxes all over you and you will drown in it. You’re fucking quantum, kiddo.
Tags:
#physics #anything that makes me laugh this much deserves a reblog #this probably deserves some warning tag but I am not sure what #this post was queued because my to-reblog list is too long and I didn’t want to dump it on you all at once
I was walking through the toy aisle at Target when I found this thing and had a VIOLENT AND IMMEDIATE FLASHBACK to when JP first came out and they had a bunch of REALLY COOL T Rex toys that I would have sold one of my scrawny small-child limbs for but my mother wouldn’t get me one because they were “too violent and also ate people” :(
on closer inspection, it makes a lot of really obnoxious noises and is also Too Expensive. BUT FEAR NOT I found this slightly smaller dude wedged in the back!
IT HAS BITE ACTION, AND THAT’S THE ONLY THING THAT MATTERS
update update: I re-sized her collar and found a bag of toy bones at the craft store. I haven’t put this much effort into a non-school thing since my last job search, help
hey! HEY. it’s Halloween 2023! AND YOU’LL NEVER GUESS WHAT WEXTER IS DRESSED UP AS THIS YEAR.
she’s… (WEXTER! here girl!) she’s a… a…..
she’s a T. Rex.
GOTTEM!
Tags:
#happy Radical Saturday #dinosaurs #Jurassic Park #anything that makes me laugh this much deserves a reblog #long post #this post was queued to ensure proper timing